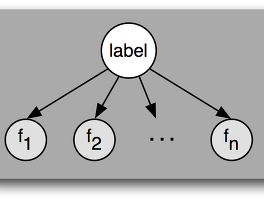
확률 (2) 썸네일형 리스트형 비모수 베이지안 모델(Bayesian Nonparametric Models) 기계학습(Machine Learning) 분야에서 통계나 확률적인 방법으로 접근하여 문제를 해결하려고 시도하는 것은 자연스러운 접근방법일 것이다. 이미 어떤 데이터를 학습시킬 것인지 그 데이터의 특성을 우리가 사전에 완전히 알고 있다면 모를까, 대부분 그렇지 않을 것이고 따라서 불확실성(uncertainty)을 데이터가 가지고 있다고 봐야하기 때문에 그 데이터를 커버할 수 있는 학습모델을 선정할 때에 가장 먼저 자연스럽게 떠오르는 것이 확률적 방법일 것이라 생각한다. 기계학습분야에서 통계적 방법을 사용하는 이유는, 데이터들이 가지는 어떤 특징들의 분포(distribution)를 보고 다음에 들어오는 새로운 데이터가 어디에 많이 포함되는지를 보고 그 데이터를 분류하기 위한것이다. 그런데.. 우리가 학습문제.. 나이브 베이즈(Naive Bayes) (image from Google.) 어떤 뚜렷한 원인은 알 수 없으나, 기존에 모아놨던 데이터에서 어떠한 인과관계를 분석하여 결과를 예측할 때 확률이라는 것은 좋은 도구로 사용될 수 있다. 예를들어, 병을 진단할때, 정확하지는 않지만 흔히 기침을 하거나 몸에서 열이나고 콧물이 나거나 하는 등의 증상이 보이면 우리는 감기라는 것을 예측할 수 있다. 즉, 이런 {f1, f2, f3...} 라고 하는 정보들로 감기라는 {label}을 예측할 수 있다. 다른 예를 들어볼까.. 흔히 쉽게 설명하기 위해 문서의 분류문제(document classification)나 스팸 메일의 분류문제(spam mail classification)를 많이 예로 설명한다. 스팸 메일의 분류문제를 예로들어보면, 스팸으로 분류할 것이.. 이전 1 다음